VCF 9.1 Private AI Services: How to Run Enterprise AI On-Prem With MCP Support, Blackwell GPUs, and 91% Lower TCO Than Public Cloud
VCF Private AI Services in 9.1 adds MCP governance, NVIDIA Blackwell and AMD MI350 GPU support, DirectPath I/O, CPU-based inferencing, and AI metrics dashboards — giving enterprises a complete private AI platform at a fraction of public cloud cost.
Every Enterprise Wants AI. Most Are Stuck.
The demand is clear. IDC predicts AI solutions and services will generate a global impact of $22.3 trillion by 2030. Every CIO has AI on the roadmap. But when you sit down with infrastructure teams and ask what is actually blocking deployment, the same problems come up every time.
Privacy. Enterprises need to train and customize models with their own data — customer records, financial models, proprietary IP. Sending that data to a public cloud API is a non-starter for most regulated industries and an uncomfortable compromise for everyone else. IDC surveyed 400+ enterprises with AI deployments and found that privacy, security, and control consistently rank as the top concerns — a finding that has held steady for over two years and is projected to increase further.
Cost. AI infrastructure is expensive to architect and rapidly evolving. New vendors, new SaaS components, and bleeding-edge software launch continuously. Without a platform approach, every AI project becomes a bespoke infrastructure build that is expensive to create and expensive to maintain.
Complexity. Data scientists spend weeks assembling the infrastructure they need — selecting VM classes, configuring Kubernetes clusters, provisioning vGPUs, installing NGC containers. The resulting environment may not be compliant, may not scale, and often cannot be replicated across teams.
VCF Private AI Services was built to solve all three. And version 9.1 makes a significant leap forward.
What VCF Private AI Services Actually Is
VCF Private AI Services is not a standalone product. It is a set of capabilities integrated directly into VMware Cloud Foundation — now part of the VCF subscription — that transform your existing private cloud platform into an enterprise AI platform.
The architecture has three layers working together. VCF provides the infrastructure foundation — compute, storage, networking, security, and operations for all workloads, AI and non-AI alike. The Private AI Services layer sits on top, delivering capabilities specifically designed for AI deployments: model governance, GPU management, agent building, and observability. And the AI runtime layer — NVIDIA AI Enterprise or AMD's ROCm stack — provides the model serving, inference optimization, and GPU software.
The key insight is that AI is treated as just another workload on VCF. The same DRS, HA, vMotion, and security policies that protect your production VMs protect your AI workloads. No separate management stack. No separate operations team. No separate security model.
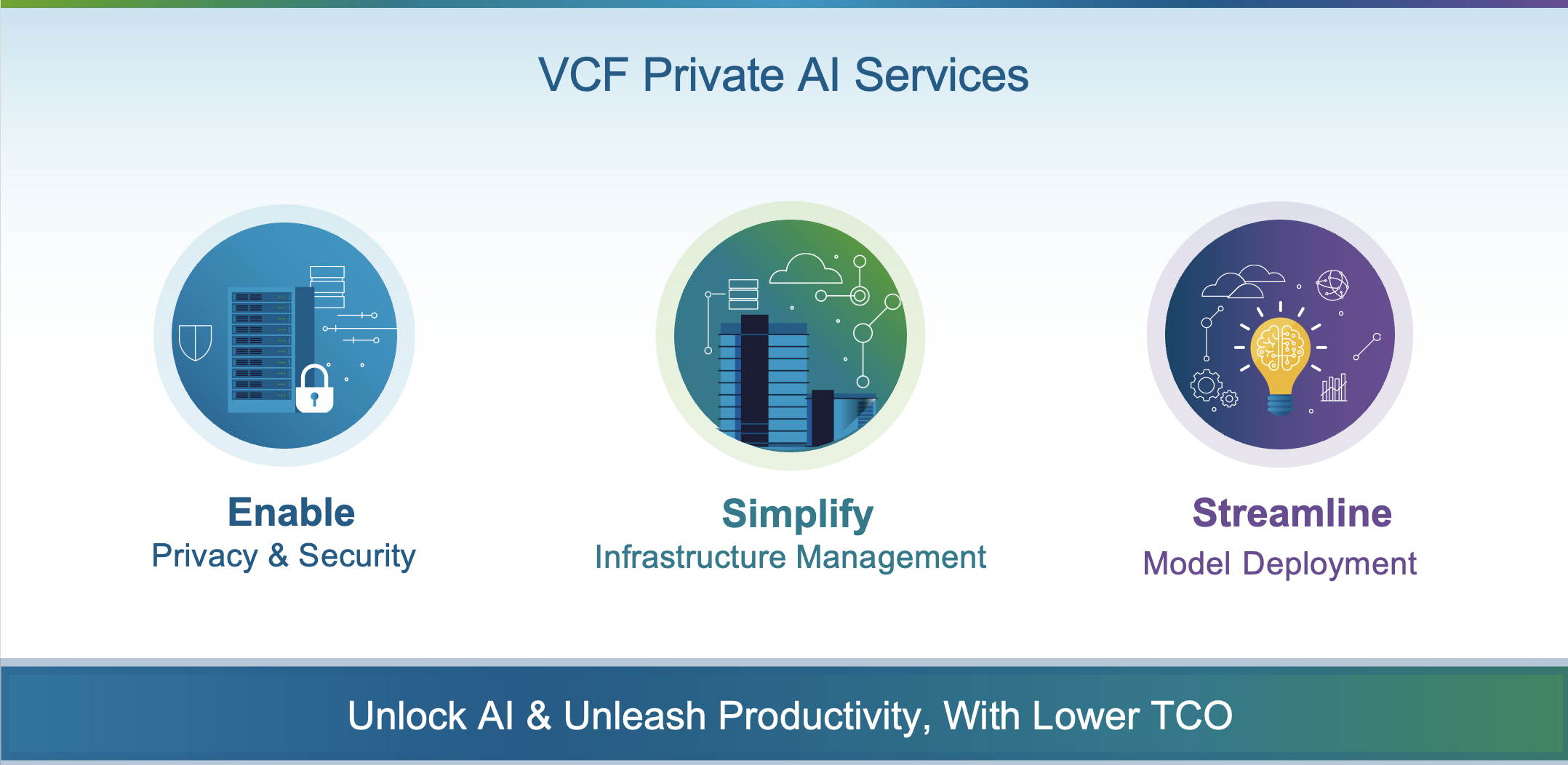
Three pillars organize the capabilities:
Enable Privacy and Security — Model Gallery with RBAC, air-gap support, MCP governance, VM encryption, Secure Boot, vTPM, and software security patching through NVIDIA AI Enterprise.
Simplify Infrastructure Management — vGPU Profile Visibility, AI Blueprints Quick Start, Deep Learning VM Templates, Guided Deployment, Vector Databases for RAG, and GPU/vGPU monitoring.
Streamline Model Deployment — Model Runtime for endpoint management, Agent Builder Service, API Gateway, Data Indexing and Retrieval Service, and CPU-based inferencing.
What's New in VCF 9.1
MCP Support with Governance
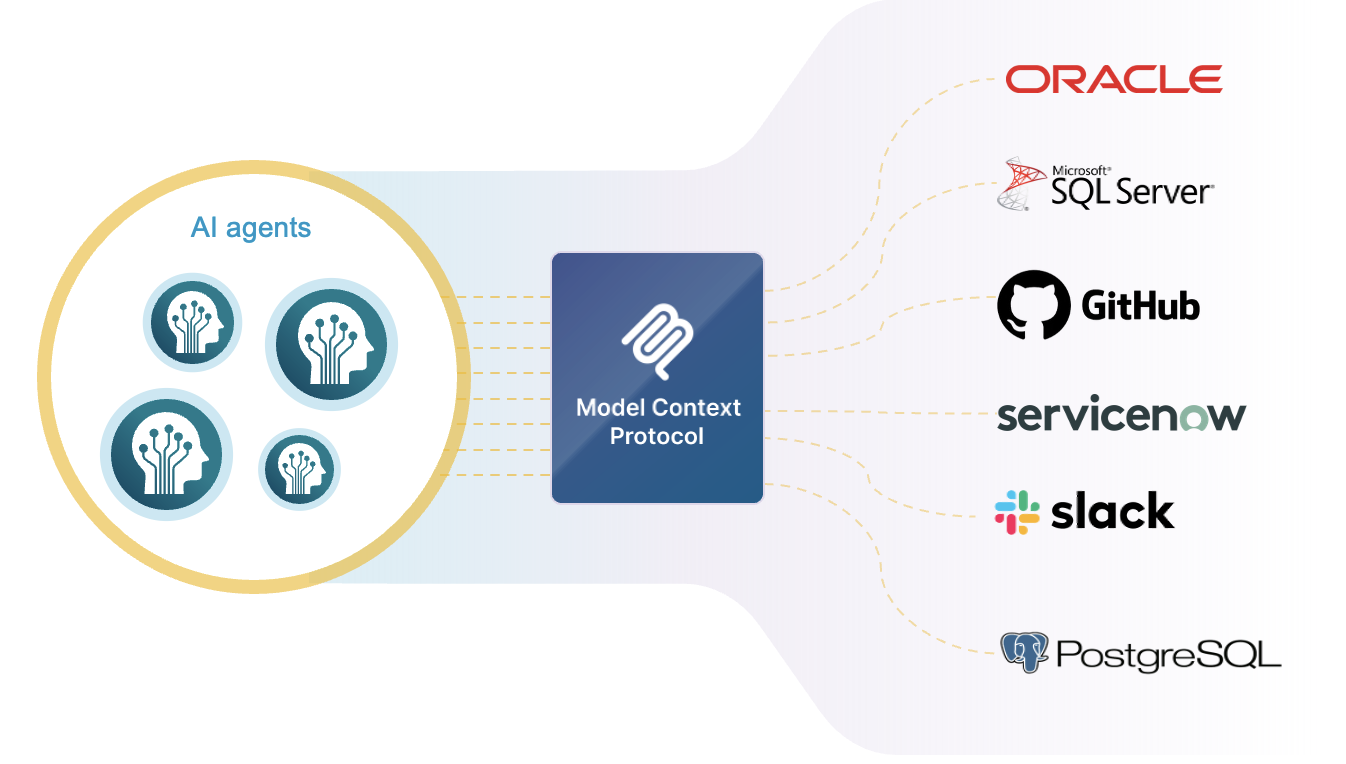
This is the headline feature for anyone building AI agents. Model Context Protocol (MCP) provides a standardized method to integrate AI agents with external tools — Oracle, Microsoft SQL Server, ServiceNow, GitHub, Slack, PostgreSQL, and more — without building custom connectors for each one.
What makes this different from just enabling MCP in your environment is the governance layer. VCF wraps MCP with enterprise-grade access controls, ensuring that AI agents can only reach the data and tools they are authorized to use. For enterprises deploying agentic AI workflows, this is the difference between a proof of concept and a production deployment.
NVIDIA Blackwell GPU Support

VCF 9.1 adds support for two new NVIDIA GPUs:
NVIDIA RTX PRO 4500 — positioned for AI inferencing workloads. This gives enterprises a cost-effective entry point for running inference at scale without dedicating H100-class hardware.
NVIDIA HGX B200 — engineered for both training and inference at unprecedented scale. The HGX platform combines Blackwell GPUs with NVSwitch, providing 900 GB/s GPU-to-GPU communication across 8 GPUs per node. This is the "AI factory" hardware, delivering up to 15x faster real-time inference and 12x lower cost and energy consumption compared to the previous Hopper generation.
With NVSwitch, enterprises can now run massive-scale AI deployments on VCF — large language model training and inference that previously required bare-metal infrastructure — while retaining all the benefits of virtualization: vMotion, HA, DRS, and Live Patching.
DirectPath Enablement for GPUs
A simpler infrastructure path for AI. DirectPath provides high-performance, exclusive GPU access directly to a VM, bypassing the vGPU mediation layer. This gives enterprises a lower-cost entry point for AI experimentation and prototyping — you get bare-metal GPU performance without needing NVIDIA AI Enterprise licensing for vGPU.
For production workloads that need shared GPU access across multiple VMs, vGPU remains the right choice. DirectPath is for the team that wants to start an AI project tomorrow without waiting for a full vGPU deployment.
Enhanced DirectPath I/O with NVIDIA ConnectX-7 and BlueField-3
For multi-node AI training, VCF now supports NVIDIA ConnectX-7 and BlueField-3 Super NICs with Enhanced DirectPath I/O. This enables GPUDirect RDMA and GPUDirect Storage — ultra-low latency direct data pathways between GPUs across hosts.
The critical detail: you keep vMotion, HA, DRS, and Live Patching. Previous multi-node GPU training setups required sacrificing these enterprise features. Now you get the networking performance of bare-metal with the operational benefits of virtualization.
Expanded AMD Partnership: MI350 Series GPUs
VCF 9.1 introduces support for AMD Instinct MI350 Series GPUs — a significant expansion of the platform beyond NVIDIA-only infrastructure.
The numbers are compelling. The MI350 delivers 10 PetaFLOPS of FP4/FP6 throughput — a 4x generational increase over previous AMD GPUs. With 288 GB of HBM3E memory, a single MI350 can run models with up to 520 billion parameters. That is a 520B parameter model on one GPU, which dramatically reduces the number of GPUs needed and directly lowers infrastructure costs.
The AMD integration brings standard enterprise virtualization features: vSphere HA for automated AI workload recovery, ESX Live Patch for non-disruptive security updates, Storage vMotion and snapshots for continuous operations, and hot add/remove of virtual hardware for dynamic scaling.
For teams that want framework flexibility, AMD's stack is built on open standards: native PyTorch and vLLM support for workload portability, OPEA (Open Platform for Enterprise AI) for standardized RAG and GenAI blueprints, and access to 1.8 million+ open-source models through Hugging Face.
AI Metrics Dashboard
New visibility into both model and GPU metrics. Data scientists and admins can now monitor GPU temperature, memory utilization, compute usage, encode/decode utilization, and model cache pressure — all from within the VCF management plane.
This matters for TCO optimization. If GPU temperatures are running high, performance degrades. If expensive GPUs are underutilized, you are wasting money. If a model's cache memory is filling up, throughput drops. Having this visibility in the same dashboard where you manage the rest of your infrastructure means you can actually act on it.
CPU-Based Inferencing

Not every inference workload needs a GPU. VCF 9.1 integrates Model Runtime with the Llama.cpp inferencing engine, enabling cost-efficient AI inferencing on standard CPU infrastructure. For smaller models, lightweight chatbots, or environments where GPU budget is constrained, this opens up AI deployment without GPU procurement.
Google Workspace Support for RAG
The Data Indexing and Retrieval Service now supports Google Docs, Sheets, and Slides as knowledge base sources for RAG pipelines. Combined with existing support for PDFs, CSVs, PowerPoint files, Microsoft Office documents, and internal web/wiki pages, enterprises can now build comprehensive knowledge bases from the tools their teams already use.
The TCO Story
Broadcom's TCO analysis shows significant cost advantages over both public cloud and bare-metal deployments. On average, VCF Private AI Services delivers up to 85% lower TCO compared to public cloud AI services and meaningful savings over bare-metal alternatives.
The primary drivers: on-premises deployment eliminates the "cloud tax" and token-based billing unpredictability — you pay for infrastructure, not per API call. Resource sharing through DRS dynamically places AI workloads across hosts, vGPU enables GPU sharing across VMs, and you use the same management and operations tools for AI and non-AI workloads. No separate AI management stack means fewer tools, fewer processes, and lower operational overhead.
Additionally, VCF Private AI Services is an open platform supporting NVIDIA models, AMD hardware, and open-source models from Hugging Face — unlike some cloud alternatives that lock you into a single model provider.
These numbers will vary based on your environment, workload mix, and scale. But the structural advantages are real: predictable pricing, resource sharing, no separate AI operations stack, and the ability to run open-source models without per-token billing.
Customer Momentum
Enterprises across education, financial services, government, and multiple other verticals have deployed VCF Private AI Services in production since its release. These are not proof-of-concept deployments — they are production platforms serving real users with real data governance requirements.
Common patterns across deployments include GPU-as-a-Service for data scientists and developers, multi-tenant AI environments with per-team isolation, air-gapped deployments for sensitive workloads, and RAG applications built on private enterprise data. Organizations consistently cite privacy, security, and cost predictability as the primary reasons for choosing an on-premises AI platform over public cloud alternatives.
Air-Gap Support: The Feature Nobody Talks About
For defense, intelligence, financial services, healthcare, and any organization handling classified or highly sensitive data, air-gap support is not optional — it is a requirement.
VCF Private AI Services can be deployed in fully air-gapped environments. All AI infrastructure elements — Deep Learning VM templates, NGC catalog objects, vGPU drivers, Quick Start capabilities — can be sourced from on-premises repositories with no outbound network calls. Downloads that normally pull from NVIDIA's NGC catalog are redirected to admin-controlled local repositories.
This means organizations that previously could not touch AI because of network isolation requirements can now deploy the full platform. Same model governance, same agent builder, same observability — just without any data leaving the building.
Who Should Care
If you already run VCF, Private AI Services is included in your subscription. You are not buying a new product — you are activating capabilities that are already there. The activation path is straightforward: assess your GPU needs, provision NVMe or add GPUs, and start deploying through the Guided Deployment workflow.
If you are evaluating AI infrastructure platforms, the question is whether you want a platform that treats AI as a separate world with separate tools, separate operations, and separate security — or one that integrates AI into the same infrastructure platform you use for everything else.
If you are running AI on public cloud and the cost is unsustainable, the TCO comparison is worth modeling for your specific workloads. Token-based billing for inference-heavy applications can spiral quickly. On-premises deployment with open-source models eliminates that variable entirely.
If you need AMD GPU support, VCF 9.1 is one of the first enterprise platforms to support the MI350 series with full virtualization features. The combination of 288 GB HBM3E memory and 10 PetaFLOPS throughput, running on an open framework stack, is a compelling alternative to NVIDIA-only infrastructure.
The Bottom Line
VCF Private AI Services has evolved from a set of initial capabilities in VCF 9.0 to a comprehensive enterprise AI platform in 9.1. The additions — MCP governance, Blackwell and MI350 GPU support, DirectPath I/O, CPU-based inferencing, AI metrics observability, and Google Workspace RAG support — address the specific friction points that have kept enterprises from scaling AI beyond pilot projects.
The structural advantage remains the same: AI is just another workload on VCF. One platform, one operations model, one security posture. That simplicity is what makes the TCO numbers work, and it is what makes production deployments possible for teams that do not have dedicated AI infrastructure engineers.
If your organization is serious about private AI — not as a buzzword but as a production capability — VCF 9.1 is worth evaluating.
References:
Discussion
No comments yet. Be the first to start the discussion.